Welcome back to my blog where we explore the latest trends and technologies in Data Engineering, Data Science, and Data Analysis. Today, we’re going to delve into the fascinating world of machine learning and its diverse applications across various industries. You may have heard terms like AI, machine learning, and deep learning used interchangeably, but it’s important to understand the unique roles each plays. Our focus will be on how machine learning, in particular, is transforming different sectors and driving innovation. Understanding these applications is essential for anyone interested in the evolving landscape of data and technology.
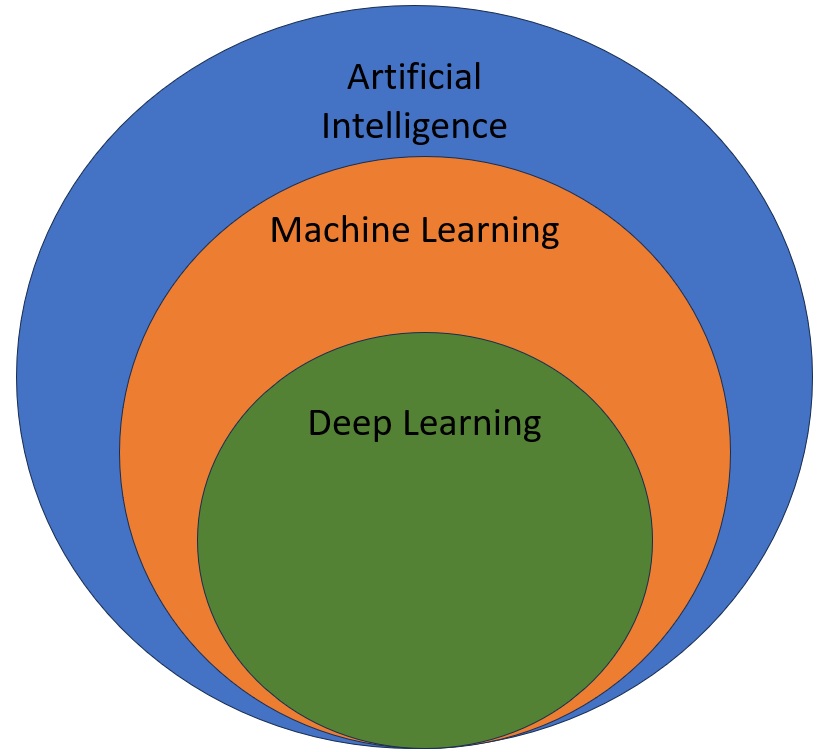
If you don’t already know, artificial intelligence, machine learning, and deep learning are not the same thing. These terms are often used interchangeably, but that’s not accurate. However, they are related. Let’s start with artificial intelligence. AI has actually been around since the 1950s. It is an overarching term that refers to enabling computers to mimic human behavior. A classic example is a computer playing chess against a human.
Machine learning is a subset of AI, and we’ll build out a more complete definition of that shortly. At its core, machine learning involves algorithms that learn and improve performance over time by using data. For instance, you can pass a dataset about credit card fraud to a computer. The computer learns from this data and can then predict if new transactions might be fraudulent. Deep learning is a subset of machine learning. It focuses on neural networks, which are artificial representations of how the human brain works. Examples include convolutional neural networks (CNNs) and recurrent neural networks (RNNs). Deep learning is used in applications such as speech recognition, computer vision, recommendation engines, and more.
Now that we have a high-level overview, let’s delve deeper into machine learning. In machine learning, algorithms learn and improve performance over time using data. But what does it mean for a computer to learn from data? It is similar to how humans learn. For instance, if you grew up on a farm, you learned to identify animals like dogs based on repeated exposure to them. When you see a new dog, even if it looks different, you recognize it as a dog because it shares characteristics with dogs you have seen before. Similarly, if you see an animal that doesn’t match the characteristics of a dog, you identify it as something else.
This process is akin to how we learn to read. You learn the alphabet, recognize letters in various forms, and then combine them to understand words. For instance, you learn that the combination of letters D-A-N-I-E-L spells “Daniel”. In a similar way, a computer learns to recognize patterns in data. If you show a computer enough pictures of dogs, it will eventually learn to identify a dog based on patterns in the data.
Machine learning algorithms can be broadly categorized into supervised learning, unsupervised learning, and reinforcement learning. Supervised learning involves training a model on labeled data, meaning the data has both input and output parameters. The model learns to map inputs to outputs and can predict the output for new inputs. For example, in spam detection, the model is trained on emails labeled as “spam” or “not spam” and learns to classify new emails accordingly.
Unsupervised learning, on the other hand, deals with unlabeled data. The model tries to identify patterns and relationships in the data without any predefined labels. Clustering is a common technique in unsupervised learning, where the model groups similar data points together. An example of this is customer segmentation, where customers are grouped based on purchasing behavior.
Reinforcement learning is a bit different. Here, the model learns by interacting with an environment and receiving feedback in the form of rewards or penalties. The model aims to maximize the total reward over time. A typical example of reinforcement learning is training a robot to navigate a maze. The robot receives positive feedback for moving closer to the exit and negative feedback for hitting walls. Every robotic vacuum cleaner operates in this manner. The home is the maze, and through a system of rewards, the robot learns to find the optimal route for cleaning. By rewarding the robot for efficiently covering more floor area and penalizing it for bumping into obstacles, the vacuum cleaner improves its navigation and cleaning efficiency over time.
Machine learning starts with training data, which can be pictures, text, video, or speech. This data is passed into an algorithm that identifies patterns. At the end of this process, we have a trained model that can make predictions on new data. For example, in handwriting recognition, our training data would be a set of handwritten digits. The algorithm learns to identify each digit based on patterns in the images. Once trained, the model can recognize new handwritten digits it has never seen before.
The real-world applications of machine learning are vast. For instance, a banking application can read handwritten amounts on checks. A shipping application can scan addresses to extract zip codes. This process is called inference, where the model makes predictions based on its training. Another example is fraud detection in e-commerce. By training a model on data about fraudulent transactions, the model can predict the likelihood of a new transaction being fraudulent.
In customer service, a trained model can predict the likelihood of a customer leaving for another service provider based on data such as call frequency, plan type, and usage patterns. This prediction allows service agents to take proactive measures to retain customers. The predictions made by these models are expressed as probabilities between 0 and 1, where 0 means impossible and 1 means certain.
Companies like Amazon frequently use reinforcement learning to recommend products that may interest the buyer. Amazon monitors which product suggestions a buyer clicks on and which ones they disregard. Using this feedback, Amazon adjusts subsequent product recommendations to better match the buyer’s preferences. This system of rewards and penalties allows Amazon to continuously refine its recommendation algorithms, resulting in increasingly personalized and relevant product suggestions for each customer.
In the realm of healthcare, machine learning is being used to predict disease outbreaks, diagnose illnesses, and personalize treatment plans. For example, models can be trained on patient data to predict the likelihood of diseases such as diabetes or heart disease. Additionally, machine learning algorithms can analyze medical images to identify anomalies such as tumors or fractures, often with greater accuracy than human radiologists.
In finance, machine learning algorithms are used to detect fraudulent transactions, assess credit risk, and even automate trading. By analyzing patterns in transaction data, these models can identify unusual activity that may indicate fraud. Credit risk models can evaluate the likelihood of a borrower defaulting on a loan by examining their financial history and other relevant data.
In education, machine learning can be used to personalize learning experiences for students. Adaptive learning platforms analyze student performance data to tailor educational content to the individual needs of each student. This can help improve learning outcomes by providing targeted support where it is needed most.
In the field of robotics, machine learning enables robots to perform complex tasks such as object recognition, path planning, and manipulation. For instance, robots equipped with computer vision algorithms can identify and pick up specific objects from a cluttered environment, a capability that is essential for applications like automated warehouse sorting.
The automotive industry is another area where machine learning is making significant strides. Self-driving cars rely on a variety of machine learning algorithms to interpret data from sensors and cameras, allowing them to navigate roads, avoid obstacles, and follow traffic rules. These algorithms must be trained on vast amounts of driving data to ensure they can handle a wide range of driving scenarios safely.
In the entertainment industry, machine learning is used to enhance user experiences through recommendation systems. Platforms like Netflix and Spotify analyze user preferences and behavior to recommend movies, TV shows, and music that users are likely to enjoy. These recommendations are generated by models that learn from the data of millions of users, identifying patterns and trends to deliver personalized content.
When considering machine learning for a task, it is important to determine if it is too complex to code manually, not cost-effective to do manually, if there is sufficient training data available, and if the problem can be framed as an ML problem. Conversely, machine learning should not be used if there is insufficient data, if the data cannot be labeled, if a quick solution is needed, or if there is no room for error.
Now that we have established the criteria for using machine learning, let’s delve into a specific and powerful subset of it: deep learning. This approach leverages neural networks to perform even more complex tasks and uncover deeper patterns within the data.
First, let’s revisit our definition of machine learning. We said it starts with data, which is passed into an algorithm that identifies patterns, and at the end of the process, we have a trained model. To simplify, we have input, we process that input, and then we have output. For example, the input could be a transaction date, a customer name, and the fact that a credit card was reported stolen. This data is fed into the algorithm, it processes the data, and the output is a prediction that this is a case of fraud. In this case, we have limited known data for input and just two options for output: either fraud or not fraud.
But what if we have something more complex? Take, for instance, a handwritten digit like the number 9. This image is 28 pixels by 28 pixels, which totals 784 pixels for a single digit. Now, imagine dealing with even more complex images, like those of people, or audio streams that need to be interpreted. Sticking with our example of the digit 9, let’s walk through the process. Each of the 784 pixels in the image is input into the neural network.
The next step involves hidden layers, of which there can be one or more. There’s both art and science in determining the number of layers and the number of nodes in each layer. For this example, let’s assume we have three hidden layers with some number of nodes in each. These layers process the input data. The nodes in the first hidden layer are connected to the nodes in the second hidden layer, and these nodes are connected to the nodes of the third hidden layer. The connections are called edges. Finally, we have the output layer, where the goal is to identify the handwritten digit as a 9. This entire structure, from input to hidden layers to output, is known as a neural network.

In the hidden layers, the neural network identifies patterns. It analyzes the pixels in specific patterns, identifying lines and loops that make up parts of the digit. For example, it can detect a straight line that might form part of a digit or loops that are part of the number 9. Through this process, the network gradually builds a complete picture of the digit.
Now, let’s break down what’s happening under the hood with a simple example involving just a few neurons. Suppose we have three input values: 1, 5, and 7. Each input value is connected to a neuron in the next layer through edges, each with an associated weight. These weights might be arbitrary numbers, such as 2, 1, and 4. When we multiply these weights by their respective input values, we get 2 (1*2), 5 (5*1), and 28 (7*4). Summing these values gives us 35 in the middle node.
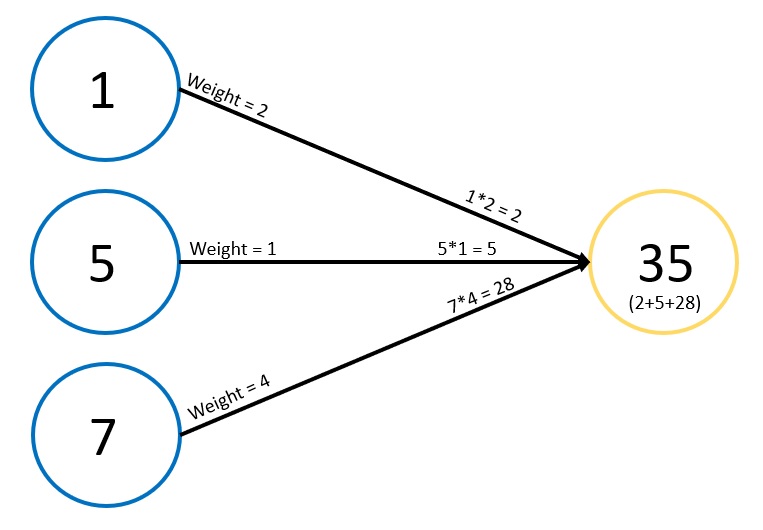
At this point, a couple of things happen. First, we apply an activation function. A common activation function ensures that the output is between 0 and 1, or in some cases, between -1 and 1. Each node also has a bias associated with it, which gets added in. The result of this processing is the output value of the node. This example illustrates just a few nodes; a complete neural network involves many such nodes and layers.
The process repeats many times. When we get to the final output, we compare it to the expected output. The difference between these two values is the cost or error. The goal of the learning process is to minimize this cost. As the algorithm iterates through the data, it adjusts the weights and biases to find the optimal combination that reduces the error. This continuous tweaking and adjustment is how the model learns. If you want to learn more about cost, be sure to check out my last article.
Deep learning’s ability to identify complex patterns in data makes it incredibly powerful for tasks like image recognition, where subtle differences and detailed features must be discerned. For example, recognizing a handwritten digit involves distinguishing minute variations in pixel arrangements, which neural networks excel at.
Deep learning models are utilized for a variety of applications. In image recognition, these models can identify objects, faces, and even emotions in photos. In speech recognition, they can transcribe spoken language into text, understand context, and even detect accents and nuances in speech.
One key advantage of deep learning is its scalability. With access to large datasets and significant computational power, deep learning models can achieve high levels of accuracy and performance. However, this also means that training deep learning models can be resource-intensive and time-consuming. The iterative process of adjusting weights and biases requires substantial computational resources, often involving powerful GPUs or specialized hardware.
I hope this article has given you a feel for what AI, machine learning and deep learning are and where they are used. The impact of machine learning and deep learning on various industries cannot be overstated. These technologies are revolutionizing the way we approach problems and make decisions, driving innovation and efficiency across countless fields. From healthcare and finance to education and entertainment, the applications are vast and continually expanding. As businesses increasingly rely on data-driven strategies to stay competitive, understanding and leveraging machine learning becomes crucial. For professionals in data engineering, data science, and data analysis, staying abreast of these advancements is not just beneficial but essential. By deepening your knowledge in machine learning and deep learning, you equip yourself with the tools to not only meet current industry demands but also to anticipate and drive future technological trends. Investing in your education in this dynamic field ensures that you remain at the forefront of innovation, capable of contributing to significant advancements and solving complex, real-world problems.


Leave a comment